Essential NLP Terminology: 8 Key Concepts Every Enthusiast Should Know
Written on
Understanding Natural Language Processing
Natural Language Processing (NLP) is an interdisciplinary domain that merges linguistics, computer science, and artificial intelligence to facilitate interactions between computers and human language. It focuses on programming machines to handle and analyze extensive sets of natural language data.
If you're looking to specialize in NLP within the broader field of Data Science, it's vital to familiarize yourself with essential concepts that can advance your career. Unfortunately, many online resources presuppose a certain level of familiarity with specific terminology, which may not be the case for everyone.
The Benefits of Specialization
Becoming a specialist in your field can offer substantial long-term advantages over being a generalist.
This video discusses why relying on traditional stop word lists in NLP can be limiting and introduces superior alternatives for more effective processing.
Key NLP Terms You Should Know
By the conclusion of this article, you will have a solid grasp of some fundamental terms commonly encountered in NLP literature.
1. Corpus
The term "corpus," derived from Latin meaning "body," signifies a collection of documents. Just as a body comprises various parts, a corpus consists of multiple texts or documents. For instance, a corpus could consist of several religious texts where each individual text is considered a document.
2. Tokenization
Tokenization is a crucial preprocessing step in NLP, aimed at breaking down phrases, sentences, or entire documents into smaller units known as tokens.

3. Stemming
Stemming is a technique in linguistic morphology where variations of a word are reduced to their base form. For example, in Python, the NLTK library can be used for stemming:
import nltk
from nltk.stem.porter import PorterStemmer
words = ["walk", "walking", "walked", "walks", "ran", "run", "running", "runs"]
stemmer = PorterStemmer()
for word in words:
print(word + " ---> " + stemmer.stem(word))
4. Lemmatization
Lemmatization groups inflected forms of a word, allowing them to be analyzed as a single entity identified by its lemma. Although stemming and lemmatization have similar aims, they employ different methodologies. An example using NLTK is as follows:
import nltk
from nltk.stem import WordNetLemmatizer
words = ["walk", "walking", "walked", "walks", "ran", "run", "running", "runs"]
lemmatizer = WordNetLemmatizer()
for word in words:
print(word + " ---> " + lemmatizer.lemmatize(word))
5. Stopwords
Stopwords are common words in any language that typically do not contribute significant meaning to text. While these words are often removed in processing, caution is advised as their elimination may negatively impact classification results.
import nltk
from nltk.corpus import stopwords
nltk.download("stopwords")
print(set(stopwords.words("english")))
6. N-grams
In computational linguistics, an n-gram refers to a contiguous sequence of 'n' items from a sample of text or speech. These items can be phonemes, syllables, letters, words, or base pairs.
from nltk import ngrams
sentence = "If you find this article useful then make sure you don't forget to clap"
unigrams = ngrams(sentence.split(), 1)
bigrams = ngrams(sentence.split(), 2)
trigrams = ngrams(sentence.split(), 3)
n_grams = [unigrams, bigrams, trigrams]
for idx, ngram in enumerate(n_grams):
print(f"nN-grams: {idx +1}")
for gram in ngram:
print(gram)
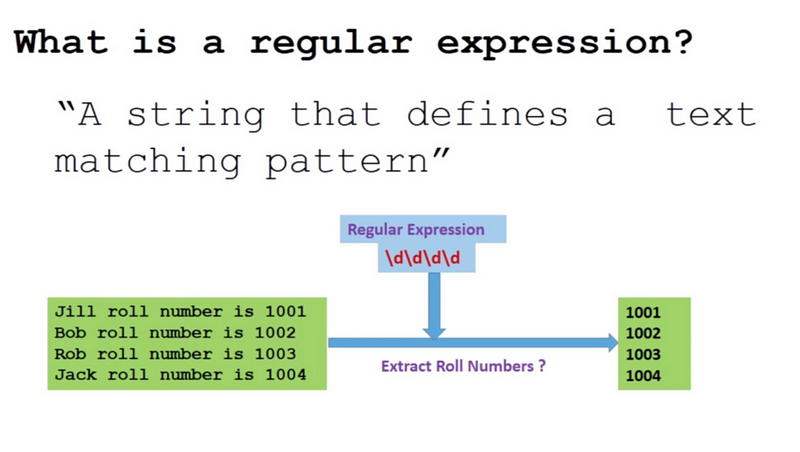
7. Regex
"Regex" stands for Regular Expression, a powerful tool for defining text patterns to match, locate, and manipulate text.
8. Normalization
Text normalization involves transforming text into a consistent form, which is crucial for effective processing. Common normalization techniques include stemming, lemmatization, and tokenization.
Wrapping Up
Navigating the world of Natural Language Processing involves mastering a variety of terms, many of which overlap among Data Scientists and NLP engineers. Understanding the concepts discussed in this article will provide a solid foundation for exploring other areas of NLP, such as Natural Language Understanding (NLU) and Natural Language Generation (NLG). Always strive to learn something new!
Stay connected with me on LinkedIn and Twitter for updates on topics related to Artificial Intelligence, Data Science, and Freelancing.