Exploring Trino: The Scalable, Open Source SQL Engine
Written on
Chapter 1: Introduction to Trino
Trino, a powerful SQL query engine designed for big data, emerged from the Presto project, which was initiated at Facebook in 2012. When some founders disagreed with its direction, they decided to launch Trino as a refined evolution of Presto after extensive discussions with Facebook. Today, Trino stands alongside other frameworks like Ahana and Starburst, all of which can be integrated with Varada.

Trino is crafted for efficiently querying vast datasets through distributed queries. For those handling terabytes or petabytes of information, it's likely that you're using tools that work with Hadoop and HDFS. Trino offers a modern alternative to traditional tools that rely on HDFS via MapReduce job pipelines, such as Hive or Pig. However, Trino is not limited to HDFS; it can also connect to various data sources, including traditional relational databases and NoSQL systems like Cassandra.
Trino excels in data storage and analysis, primarily focusing on Online Analytical Processing (OLAP). However, it's crucial to clarify what Trino is not. While many in the community refer to it as a database due to its SQL compatibility, it should not be mistaken for a general-purpose relational database. Trino is not a substitute for databases such as MySQL, PostgreSQL, or Oracle, nor is it designed for Online Transaction Processing (OLTP). This distinction is also true for numerous other databases optimized for data storage and analytics.
Despite being a relatively newer entry in the field, Trino boasts an extensive array of connectors and clients, along with robust support from business intelligence tools. Its active community and numerous enterprises using it in production highlight its growing popularity.
The video titled "Tutorial: How to contribute to open source and to Trino!" provides insights on how to engage with the Trino community and contribute to its development.
Use Cases for Trino
Trino acts as a powerful access point for SQL analytics, providing SQL-based access to data warehouses and source systems. It facilitates federated queries, offers a semantic layer for virtual data warehouses, and serves as a query engine for data lakes. With fast response times, it enhances insights across big data, machine learning, and artificial intelligence applications.
Chapter 2: Architecture of Trino
Trino's architecture consists of two primary components: the Coordinator and the Worker.
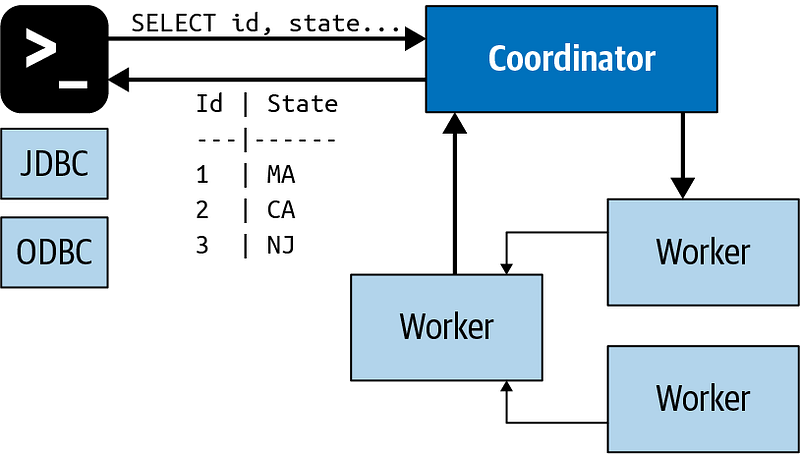
The Coordinator serves as the central server that processes SQL commands from users, plans queries, and manages worker nodes. It is the brain of the Trino installation and interfaces with clients through the Trino CLI, JDBC, ODBC drivers, or various client libraries. The Coordinator handles SQL commands and executes SELECT queries.
For development or testing, a single Trino instance can function as both the Coordinator and Worker. The Coordinator monitors each Worker’s activity and orchestrates query execution by constructing a logical plan comprising several stages.
The Workers are servers within a Trino installation that execute tasks assigned by the Coordinator and process data. They fetch data from various sources through connectors and share intermediate results with each other. The final output is sent back to the Coordinator, which then relays the results to the client.
The Workers use HTTP-based protocols to communicate with each other and the Coordinator, with the ability to register with a discovery service during initialization.
Connectors and Clients
Trino supports a multitude of connectors, enabling seamless integration with diverse data sources such as:
- Accumulo
- BigQuery
- Cassandra
- MySQL
- PostgreSQL
- Redis
- SQL Server
- And many more...
Additionally, Trino provides various clients for different programming languages, including:
- JDBC and ODBC drivers
- Command line interface
- Python client
- Node.js clients
- R and Ruby clients
Many organizations, from startups to industry giants, leverage Trino for their data analytics needs, showcasing its versatility and robust performance.
Conclusion
With Trino, you can easily execute SQL queries across multiple databases and data files located in various environments. This capability simplifies data management, but it’s essential to remember that effective query construction requires adherence to database modeling and performance principles.
Trino has established a vibrant community and is utilized by numerous companies in production environments, positioning itself as a competitive alternative to AWS Athena and Presto.
For further reading, consider "Trino: The Definitive Guide: SQL at Any Scale, on Any Storage, in Any Environment" for comprehensive insights into its capabilities.
References
- Trino documentation - Trino 377 Documentation
- PrestoDB or Trino: Boost Performance with Big Data Indexing | Varada.io
- PostgreSQL connector - Trino 379 Documentation
- Trino: The Definitive Guide
# Thank you for reading, share this post! :)