Innovative Low-Code Python Libraries for Data Science in 2022
Written on
Chapter 1: Introduction to Low-Code Solutions
The emergence of no-code and low-code machine learning platforms has significantly lowered the barriers for implementing and utilizing machine learning models within applications. Citizen data scientists now possess the capability to execute tasks that once demanded extensive programming expertise, thanks to these user-friendly platforms and frameworks.
While employing a drag-and-drop interface for training machine learning models in no-code platforms is the most straightforward approach, it often lacks the adaptability needed for more complex tasks. Conversely, low-code machine learning offers a balanced alternative that marries simplicity with necessary flexibility.
In this discussion, we will explore some of the most valuable low-code machine learning libraries available in Python. The selection presented here is subjective and not arranged in any particular order.
How are no-code and low-code tools impacting data science?
This video delves into the influence of no-code and low-code tools on the field of data science, highlighting how these tools are reshaping workflows and expanding access to machine learning capabilities.
Chapter 2: PyCaret
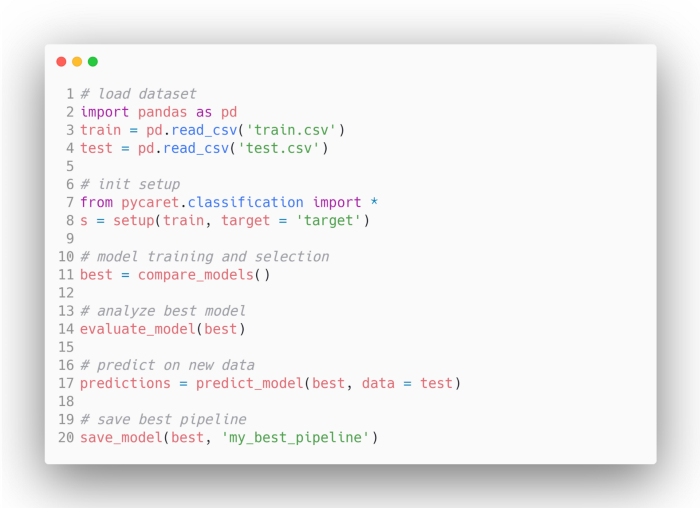
PyCaret is an open-source, low-code library that automates various machine learning workflows within Python. This end-to-end tool dramatically accelerates the experimentation process, enhancing productivity and efficiency.
Compared to other open-source libraries, PyCaret stands out by allowing users to replace extensive lines of code with succinct commands. This capability results in a more rapid and efficient experimentation cycle. Essentially, PyCaret serves as a Python wrapper around multiple machine learning libraries and frameworks, including scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, and Ray.
Chapter 3: PyTorch Lightning
PyTorch Lightning is a high-level interface designed to enhance the usability of PyTorch. With its lightweight yet high-performance architecture, it allows for the separation of research from engineering, making deep learning experiments more manageable and reproducible.
According to its official documentation, PyTorch Lightning enables you to focus more on research rather than engineering. A simple refactor facilitates the following capabilities:
- Run your code on any hardware
- Profile performance and identify bottlenecks
- Implement model checkpointing
- Achieve 16-bit precision
- Conduct distributed training
For further insights into this library, visit their official website.
Chapter 4: Hugging Face Transformers
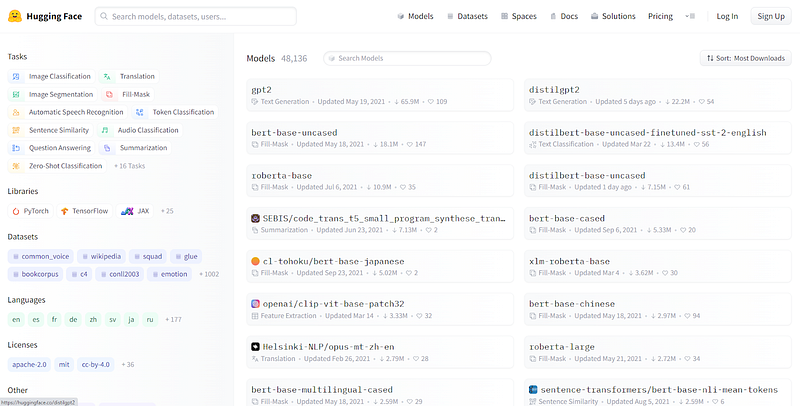
Hugging Face Transformers is an open-source library that enables quick downloading and training of state-of-the-art pretrained models. Utilizing pretrained models can significantly reduce computational costs, carbon footprints, and the time required to train new models from scratch.
The library supports various modalities, including:
- Text: Classifying, extracting information, answering questions, translating, summarizing, and generating text in over 100 languages.
- Images: Image classification, object detection, and segmentation.
- Audio: Speech recognition and audio classification.
Transformers allow seamless integration with prominent deep learning libraries like PyTorch, TensorFlow, and JAX, enabling users to train models across different frameworks with minimal code.
For more details, refer to their official website or GitHub repository.
Chapter 5: pandas-profiling
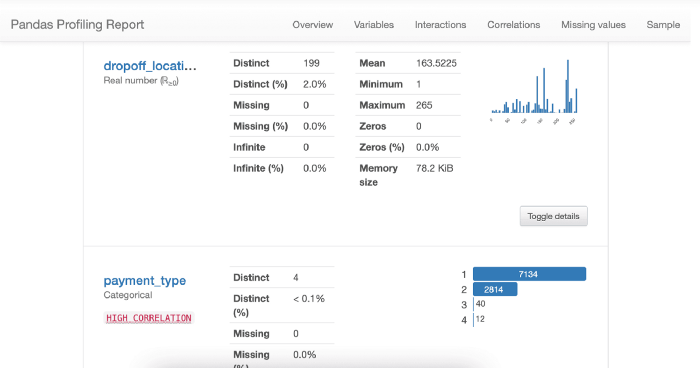
The pandas-profiling library automatically generates comprehensive profile reports from a pandas DataFrame. While the pandas describe function is useful, pandas-profiling enhances this with a low-code interface that presents detailed information for each dataset column in an interactive HTML report, including:
- Type inference: Identifying column types
- Unique values and missing values
- Quantile statistics (min, Q1, median, Q3, max)
- Descriptive statistics (mean, mode, std deviation, etc.)
- Most frequent values and histograms
- Correlation matrices (Spearman, Pearson, and Kendall)
To explore pandas-profiling further, check out their GitHub page.
Chapter 6: D-Tale
D-Tale is a user-friendly, low-code library that facilitates the viewing and analysis of Pandas data structures. It combines a Flask-based backend with a React frontend, making it compatible with Jupyter Notebook. Currently, D-Tale supports all Pandas data structures, including DataFrame, Series, MultiIndex, DatetimeIndex, and RangeIndex.
Originally developed as a SAS to Python conversion, D-Tale evolved from a Perl script wrapper into a lightweight web client for Pandas data structures.
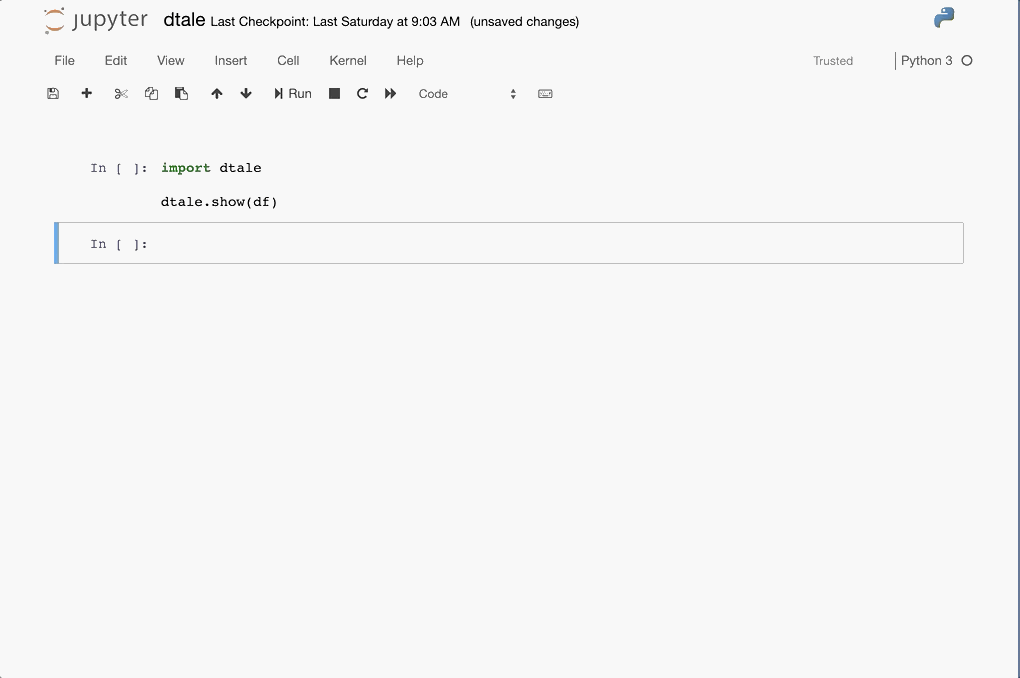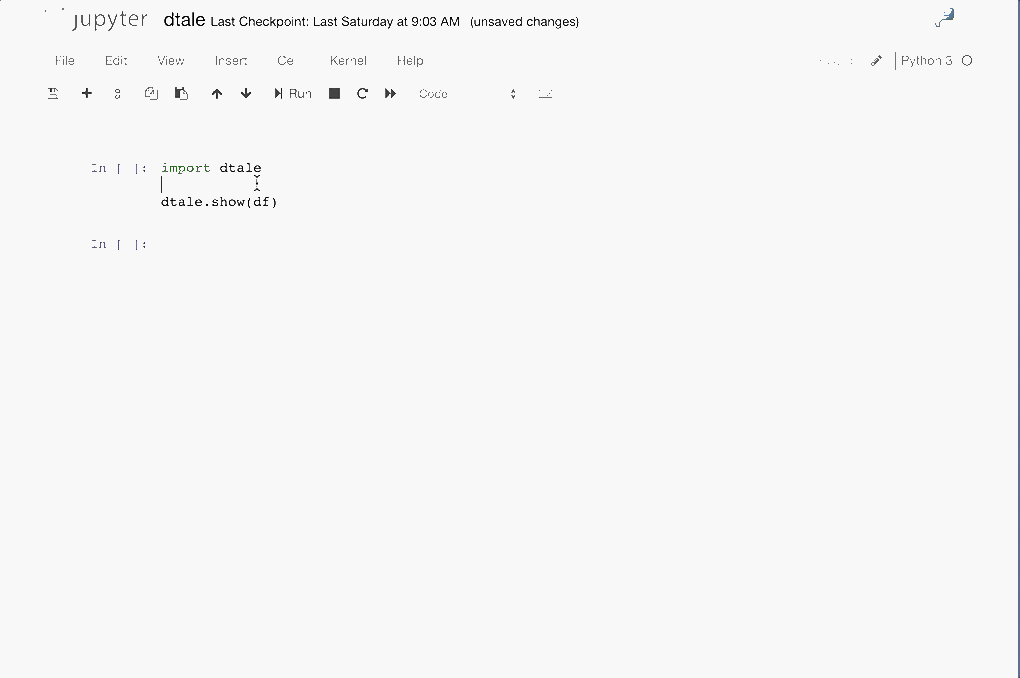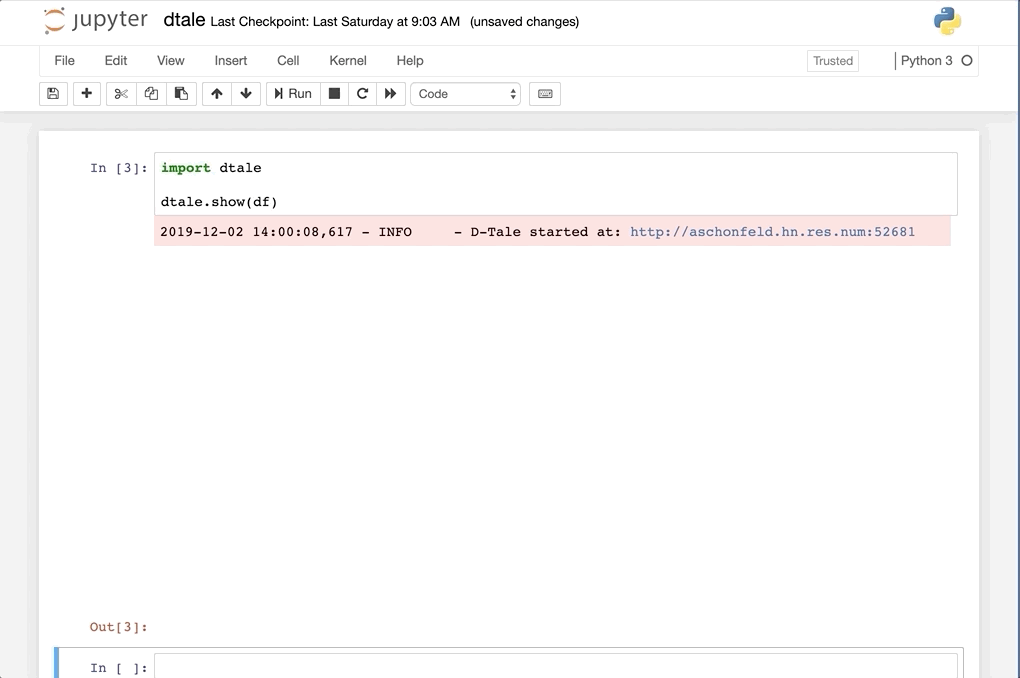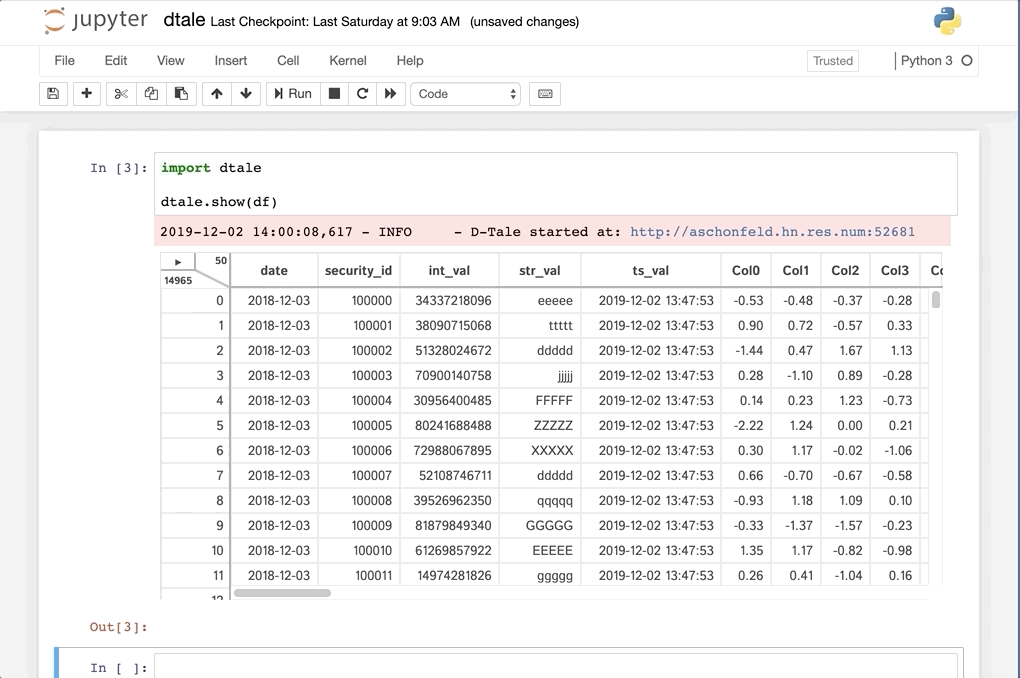
Chapter 7: AutoViz
AutoViz stands out as a low-code visualization framework, comparable in functionality to SweetViz and pandas-profiling. It requires only a single line of code to automatically visualize any dataset. AutoViz intelligently identifies the most significant features and generates impactful visual representations swiftly.
For examples and further information, check out the official AutoViz Example Notebooks.
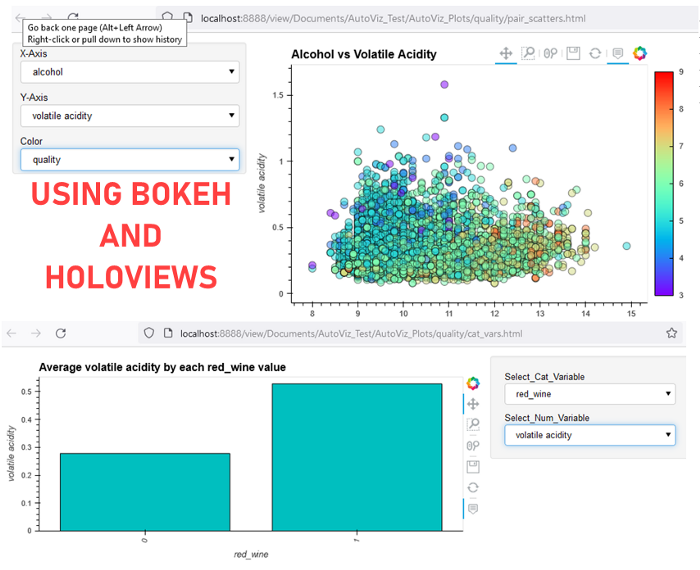
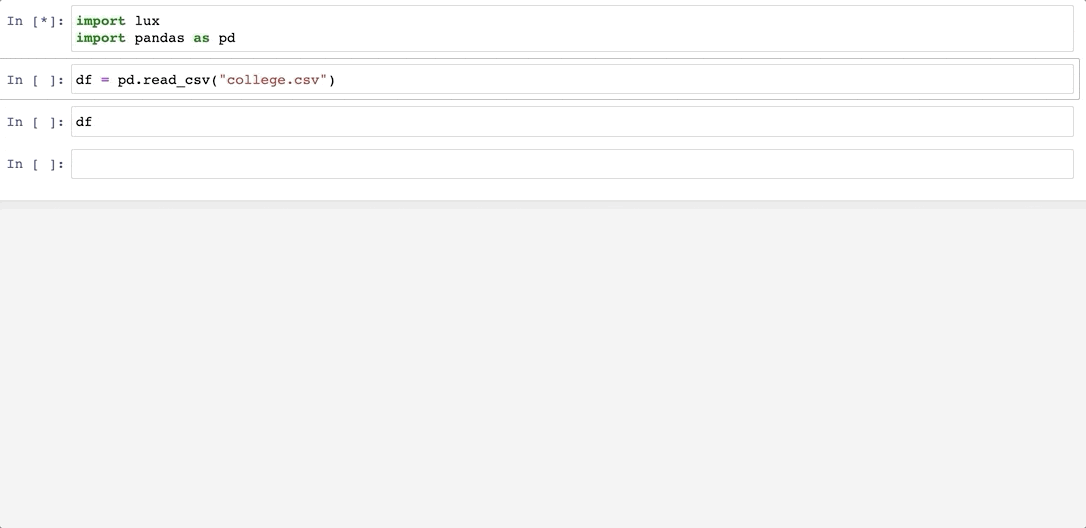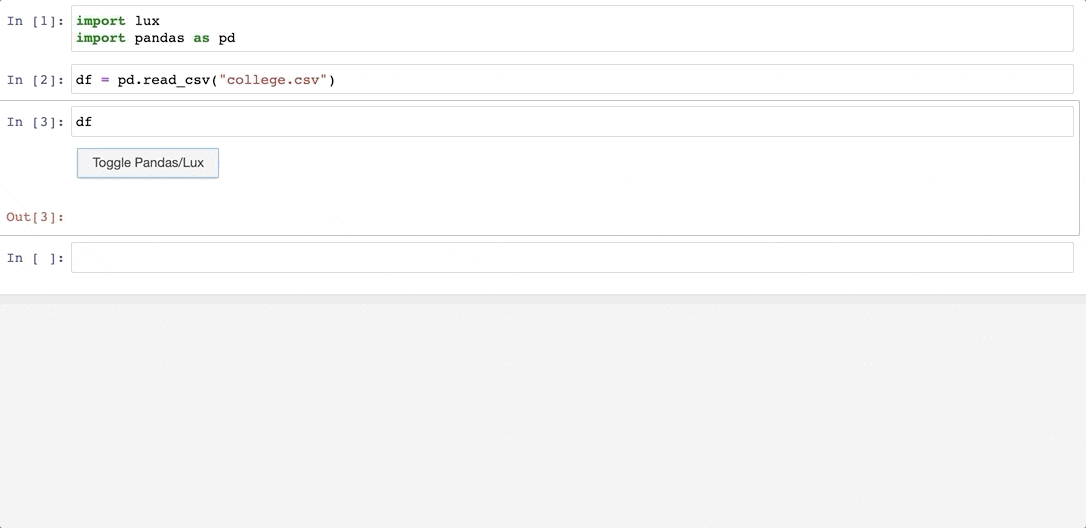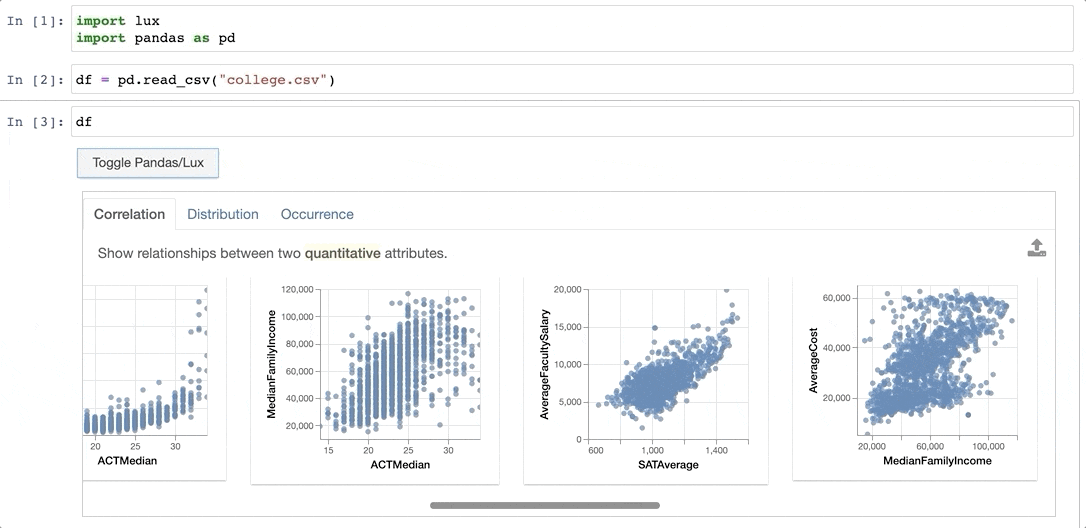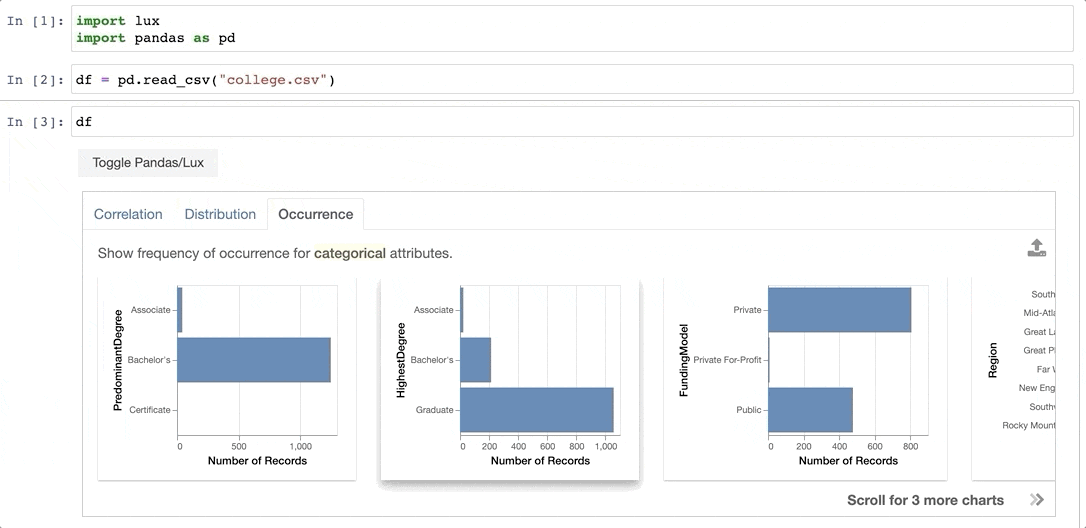
Chapter 8: Lux
Lux emphasizes visualization capabilities in Python by automatically suggesting charts based on the data provided. Instead of offering a fixed interface for chart creation, Lux proposes several potential visualizations, allowing users to choose their preferred option. This approach minimizes both the time needed for chart creation and the preprocessing required before visualizing data.
To learn more about Lux, visit their official GitHub page.
Chapter 9: Conclusion
Thank you for taking the time to read this overview of low-code Python libraries for data science. These tools not only enhance accessibility to machine learning but also streamline workflows, making them invaluable for both novice and experienced data scientists.
Author:
I specialize in writing about data science, machine learning, and PyCaret. To stay updated with my latest insights, feel free to follow me on Medium, LinkedIn, and Twitter.
Machine Learning Made Easy With PyCaret
In this video, Moez Ali discusses how PyCaret simplifies the machine learning process, making it accessible for users with varying levels of expertise.