Understanding Computer Vision: A Comprehensive Overview
Written on
Chapter 1: Introduction to Computer Vision
Computer Vision represents a branch of Artificial Intelligence focused on enabling machines to interpret and understand visual data from images and videos. While the programming aspect is vital, grasping the foundational concepts is crucial before diving into coding. This guide serves both novices and seasoned professionals, providing a concise yet comprehensive overview of key terms in Computer Vision, supplemented by mathematical functions, diagrams, and practical examples.
Let’s embark on our exploration of Computer Vision.
Content Overview:
- Introduction
- Padding
- Convolution Operations
- Valid Convolution
- Same Convolution
- Strided Convolution
- Pooling Techniques
- Average Pooling
- Max Pooling
- Prominent Networks
- LeNet-5
- Network Architecture
- AlexNet
- Network Structure
- VGG-16
- Inception Network
- Transfer Learning
- Data Augmentation
- Conclusion
Section 1.1: Padding
Padding involves adding extra layers to an image to maintain its dimensions and prevent reduction in size.
Section 1.2: Convolution Operations
Convolution is the process of applying a defined filter to an image's transformed numerical representation.
Subsection 1.2.1: Valid Convolution
In valid convolution, the output size decreases based on the filter dimensions.
Subsection 1.2.2: Same Convolution
With same convolution, the output dimensions remain consistent with the input size due to padding.
Subsection 1.2.3: Strided Convolution
Strided convolution alters the stride during multiplication operations, typically increasing it to two.
Section 1.3: Pooling Techniques
Pooling is designed to downsample the input image.
Subsection 1.3.1: Average Pooling
This method employs averaging to perform the pooling operation.
Subsection 1.3.2: Max Pooling
In max pooling, the maximum value from the relevant numbers is computed.
Chapter 2: Prominent Networks
LeNet-5 is a foundational convolutional neural network designed by Yann LeCun and his colleagues in 1998. It typically consists of the following layers:
- Convolution Layer
- Average Pooling Layer
- Second Convolution Layer
- Average Pooling Layer
- Fully Connected Convolution Layer
- Fully Connected Convolution Layer
- Output Layer - Fully Connected Softmax Output Layer
AlexNet, developed by Alex Krizhevsky with Ilya Sutskever and Geoffrey Hinton, is another influential CNN architecture characterized by:
- Convolution Layer
- Second Convolution Layer
- Third Convolution Layer
- Fourth Convolution Layer
- Fifth Convolution Layer
- Fully Connected Layer
- Second Fully Connected Layer
- Third Fully Connected Layer
- Output Layer - Fully Connected Softmax Output Layer
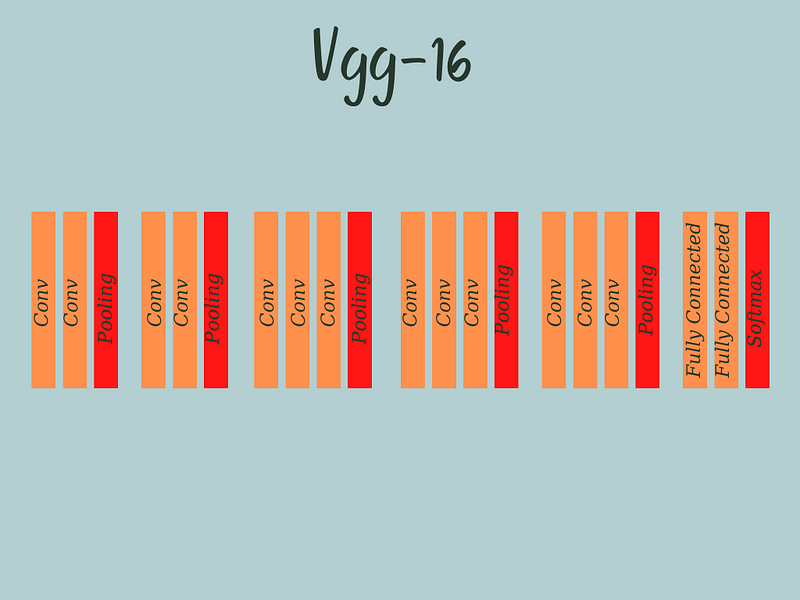
VGG-16, created by the Visual Geometry Group at the University of Oxford in 2014, is a well-known pre-trained CNN.
Section 2.1: Inception Network
The Inception Network incorporates various convolution and pooling operations simultaneously, allowing for flexibility in model design. If computational efficiency is a concern, a bottleneck layer can be utilized.
Chapter 3: Transfer Learning
Transfer learning involves utilizing an existing convolutional deep learning network to address a new problem. By modifying the last layer to fit a specific softmax function for your dataset, you can achieve impressive results, especially when classifying multiple categories.

Chapter 4: Data Augmentation
Data augmentation enhances the performance of your computer vision systems. This technique involves creating variations of your dataset through methods like mirroring, cropping, rotating, and color adjustment, ultimately improving algorithm accuracy.

Conclusion
Thank you for engaging with this article on Computer Vision. Although many more concepts exist within this field, further exploration will be reserved for the next installment. For additional structured insights into Machine Learning, Statistics, Linear Algebra, Classification, Deep Learning, and Regression, stay tuned.
If you would like to receive updates via email about similar articles and access free cheat sheets, consider subscribing to my mailing list. Typically, I send out two emails each week.
“Machine learning is the last invention that humanity will ever need to make.”
— Nick Bostrom
This introductory video provides a foundational overview of computer vision concepts, ideal for beginners.
This video breaks down computer vision in a beginner-friendly way, making complex ideas accessible.