Understanding SARSA and Q-Learning: Key Concepts and Comparisons
Written on
Chapter 1: Introduction to Reinforcement Learning
Reinforcement Learning (RL) is a domain within AI that focuses on how agents can learn to make optimal decisions through interactions with their environments. The primary goal is for the agent to discover actions that will maximize its cumulative long-term rewards. As the agent engages with its surroundings, the state of the environment evolves, resulting in the agent receiving a numerical reward. The strategies guiding these actions are referred to as policies.
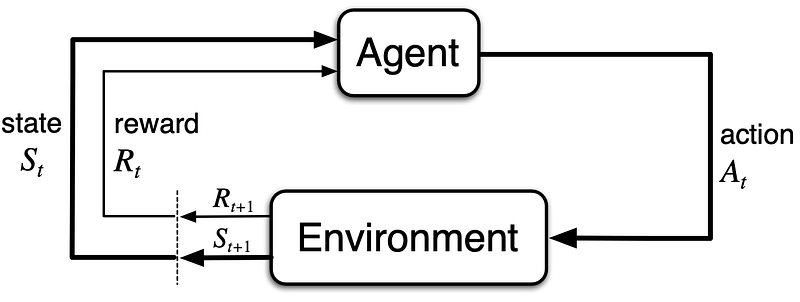
Chapter 2: Key Concepts in Temporal Difference Learning
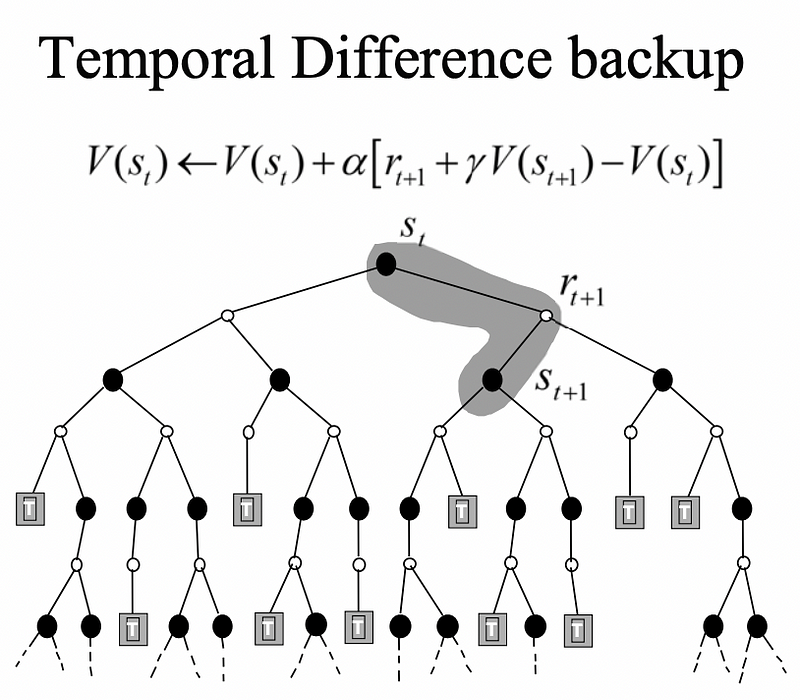
Temporal Difference (TD) learning is a crucial technique in reinforcement learning, primarily used for online predictions. This method derives its name from its use of differences over time to estimate the total expected rewards in the future.
TD learning calculates values incrementally at each step, allowing agents to learn directly from their experiences in the environment without needing a comprehensive model of its dynamics.
Chapter 3: Understanding SARSA
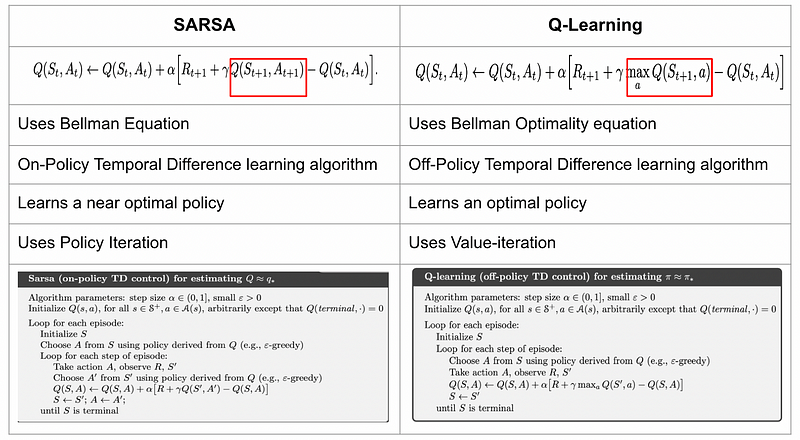
SARSA, which stands for State, Action, Reward, (Next) State, (Next) Action, is an on-policy TD algorithm that aims to derive the optimal policy by updating the state-action value function (Q) at each step using the Bellman equation. This approach allows SARSA to learn from real-time experiences while continuously updating its state-action values.
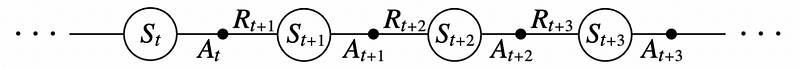
SARSA operates by transitioning between state-action pairs, learning the values associated with these pairs through its experiences. Each episode consists of a sequence of states and corresponding actions, enabling the agent to refine its decision-making process.
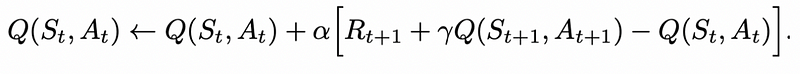
In SARSA, the agent must decide on the next state-action pair before updating its value estimates. This means it utilizes its current policy to sample the subsequent action, which influences the updates to the state-action values.
SARSA converges to a near-optimal policy, provided that all state-action pairs are explored sufficiently, ultimately leading to the epsilon-greedy policy. This policy strikes a balance between exploration and exploitation by randomly selecting exploratory actions with a certain probability.

Chapter 4: An Overview of Q-Learning
Q-Learning is an off-policy TD algorithm designed to identify the optimal policy by updating the state-action value function (Q) at each step, guided by the Bellman Optimality equation until the Q-function reaches convergence.
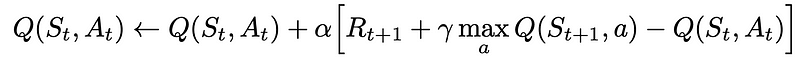
In Q-Learning, the agent begins in a state, performs an action, receives a reward, and then chooses the action that promises the highest reward for the next state. This process updates the Q-value for the action taken in the original state.
Q-Learning employs both behavioral and target policies; the behavioral policy gathers samples for the agent's experience while the target policy is optimized for performance. Through value iteration, Q-Learning systematically refines its value function to discover a policy that maximizes long-term rewards.

Chapter 5: Comparing SARSA and Q-Learning
Both SARSA and Q-Learning utilize TD prediction techniques to solve control problems. They share the similarity of estimating the action-value function by updating Q-values after each time step and employing the epsilon-greedy policy.
However, there are notable differences between the two methods. While SARSA is on-policy, updating values based on its current policy, Q-Learning is off-policy and aims to maximize the state-action value function across all possible future actions.
Conclusion: Insights and Implications
In summary, SARSA and Q-Learning represent two distinct approaches within reinforcement learning. SARSA focuses on refining the policy it uses for decision-making, while Q-Learning aims to find the optimal policy through broader exploration. Both methods rely on the epsilon-greedy strategy for balancing exploration with exploitation.
References:
Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto
The first video titled "SARSA vs Q Learning" provides an insightful comparison of these two popular reinforcement learning algorithms, discussing their strengths and weaknesses.
The second video titled "Q Learning simply explained | SARSA and Q-Learning Explanation" offers a straightforward explanation of both SARSA and Q-Learning, making it accessible for beginners.