Unpacking Mistral AI's Mixtral 8x7B: A New Era of Language Models
Written on
Chapter 1: Introduction to Mixtral 8x7B
Mistral AI's recent introduction of the Mixtral 8x7B model has stirred considerable excitement in the AI community. Headlines proclaiming that “Mistral AI Unveils Mixtral 8x7B: A Sparse Mixture of Experts Model Revolutionizing Machine Learning” have grabbed attention. This model is said to have outperformed GPT-3.5, altering the landscape of AI technologies.
Founded in 2023 by former engineers from Meta and Google, Mistral AI took an unconventional approach to launching Mixtral 8x7B. Instead of a formal announcement, they shared a Torrent link via Twitter on December 8, 2023, leading to a flurry of memes about their non-traditional marketing strategy.

The accompanying research paper, "Mixtral of Experts" by Jiang et al. (2024), was released a month later on January 8, 2024, on Arxiv. Let’s delve into its details and assess whether the excitement surrounding it is justified.
(Spoiler: The technical innovations may not be as groundbreaking as some might think.)
Section 1.1: A Brief History of Sparse MoE Models
The Mixture of Experts (MoE) framework has roots tracing back to the early 1990s. The core concept involves modeling a prediction y as a weighted sum of various experts, with a gating network determining the weights. This approach allows for the decomposition of complex problems into manageable segments, akin to the divide-and-conquer strategy.
The significant advancement that propelled MoE models was the introduction of top-k routing in the 2017 paper “Outrageously Large Neural Networks.” This innovation allows for the calculation of outputs from only the top k experts, maintaining computational efficiency even as the number of experts increases significantly.
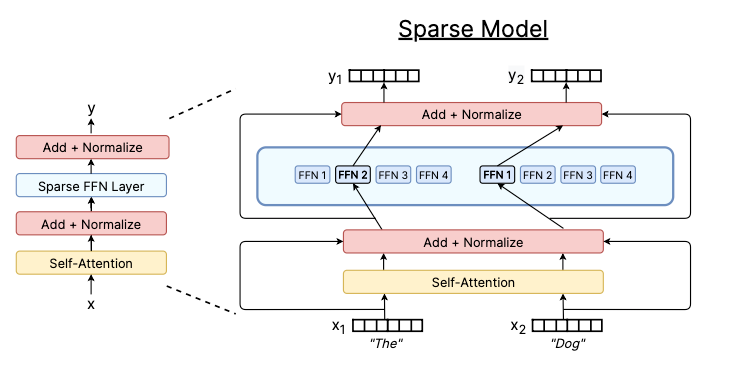
The Switch Transformer further advanced the field by utilizing a k=1 strategy, selecting only the most relevant expert for each token input. This shift in methodology challenged previous assumptions about the necessity of comparing multiple experts for effective learning.
Today, we refer to this method as "hard routing," contrasted with the softer routing seen in standard MoE frameworks. By integrating 128 hard-routed experts into the T5 Transformer and employing several innovative techniques, this approach achieved remarkable advancements in pre-training efficiency and downstream tasks.
Chapter 2: Understanding Mixtral 8x7B Architecture
In the video titled Stanford CS25: V4 I Demystifying Mixtral of Experts, the speaker provides insights into the architecture and operational mechanics of the Mixtral model.
Mixtral 8x7B is structured as a 32-block Transformer where each block substitutes the feed-forward network (FFN) layer with eight experts utilizing top-k routing with k=2. Each expert consists of a single-layer MLP employing SwiGLU activation functions. This setup yields a total of 47 billion parameters, with only 13 billion active at any moment due to the top-2 routing strategy, effectively merging large capacity with rapid training speed.
Section 2.1: Benchmark Performance
The authors of the Mixtral paper evaluated its performance across six diverse benchmark categories, including MMLU, knowledge retrieval, reasoning, comprehension, math, and coding. They compared the results against Mistral-7B, their dense 7B parameter model, along with Llama-7B, Llama-13B, and Llama-70B models.
Findings indicate that Mixtral 8x7B performs equally well, if not better, than the largest Llama model, despite using only a fraction of the active parameters. It showed significant improvements particularly in math and coding tasks.
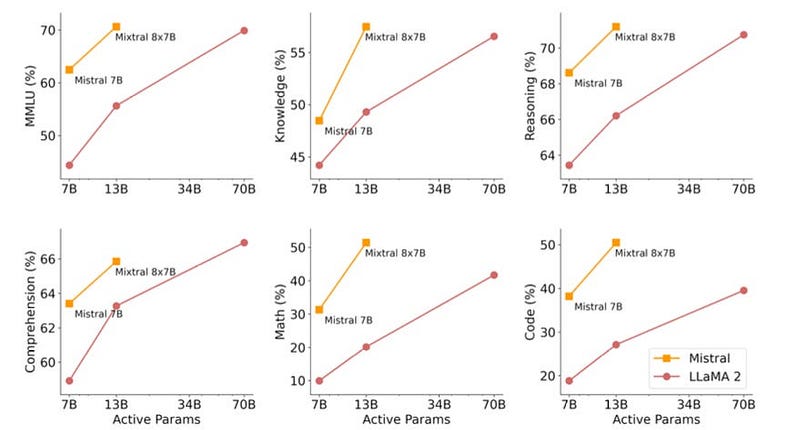
When assessed on multilingual benchmarks, Mixtral-8x7B outperformed the 70B Llama 2 model in several languages, including French, German, Spanish, and Italian. The authors attribute this success to a notable increase in the amount of multilingual data during pre-training.
Subsection 2.1.1: Mixtral-Instruct Model
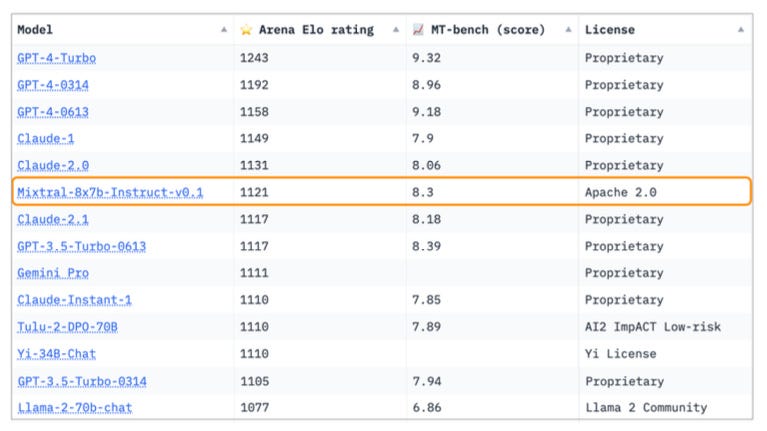
The authors also fine-tuned Mixtral 8x7B on an "instruction dataset" and found that the resulting Mixtral-Instruct model surpassed GPT-3.5-Turbo, Gemini Pro, Claude-2.1, and Llama 2 70B Chat based on human evaluations. They claim that Mixtral-Instruct is currently the leading open-weights model.
Section 2.2: Comparison with Switch Transformer
The second video titled Mixtral of Experts (Paper Explained) delves into the nuances of the Mixtral model and its differences from the Switch Transformer.
In comparing Mixtral to the Switch Transformer, several differences emerge: Mixtral employs top-k routing with k=2 versus the k=1 used in Switch. While Mixtral uses only eight experts, the Switch Transformer utilizes 128. Furthermore, Mixtral integrates experts into each Transformer block rather than alternating their placement.
Despite its innovations, Mixtral does not appear to introduce any fundamentally new concepts that were not previously established. The advantages of sparse, Transformer-based models over their dense counterparts have been recognized since the introduction of the Switch Transformer.
Section 2.3: The Nature of Expert Specialization
One unexpected result from Mixtral-8x7B is that its experts lack the clear semantic specialization observed in earlier studies. Previous research indicated that different experts would focus on distinct semantic clusters, while Mixtral's expert specialization seems to be more syntax-based, primarily organizing around word arrangement rather than meaning.
This syntactic focus may elucidate Mixtral-8x7B’s superior performance in math and coding tasks.
Chapter 3: Conclusion and Future Directions
In summary, while Mixtral 8x7B has created quite a buzz, it doesn't present any revolutionary advancements beyond what has been documented in prior research. The model's ability to outperform dense language models with a smaller parameter set is impressive but not wholly unexpected. The real challenge lies in optimizing the efficiency of sparse LLMs.
The defining feature of Mixtral is its open-source nature, allowing users to download and run the model locally. This aspect sets it apart from other models like the Switch Transformer, which do not offer this flexibility.
If you found this analysis insightful, consider subscribing to my newsletter for more updates on AI innovations!